As AI enthusiasts and practitioners, we’re always on the lookout for methods that push boundaries without drowning us in complexity. Retrieval-Augmented Generation (RAG) is one such innovation that elegantly combines the strengths of information retrieval and language generation. If you’ve wondered how RAG can supercharge AI models—from robotics to specialized medical tasks—this post is for you. Let’s unpack what RAG is, how it works under the hood, and why it’s proving so transformative across domains.
What is Retrieval-Augmented Generation (RAG)?
RAG is a hybrid AI technique that enhances text generation by integrating an explicit information retrieval step before generating responses or decisions. Unlike traditional generative models that rely solely on learned patterns during training, RAG dynamically fetches relevant data from external knowledge sources on-the-fly. This potentially broadens the model’s knowledge base dramatically, improves accuracy, and mitigates the common problem of hallucinations—where models make up plausible but incorrect information.
Imagine RAG as a smart researcher: before answering a question, it quickly searches a trusted library, picks the most relevant books or papers, and then composes a response informed by those materials rather than relying on memory alone.
Why Does RAG Matter?
1. Combatting Data Sparsity and Domain Gaps
Models trained on general data often struggle with specialized domains—medical, legal, scientific, or robotics instructions—where vocabulary and concepts are highly specific or novel. Traditional embeddings might fail to represent such terms meaningfully.
RAG, by pulling in domain-specific documents at runtime, allows models to leverage up-to-date and specialized information without the need for retraining or exorbitant fine-tuning. This is a huge advantage, especially in fast-evolving fields.
2. Continuous Learning and Adaptation
In robotics, for example, continuous adaptation to new information or human feedback is crucial. Integrating RAG enables robots to retrieve past experiences, external manuals, or updated protocols dynamically. Combined with other techniques like regret-based learning (which quantifies and minimizes errors over time), it forms the backbone of more adaptive and robust human-robot collaboration frameworks.
3. Improved Task Optimization
When models are fine-tuned with transformer architectures and augmented with retrieval, they exhibit better task performance—for instance, more accurate oncology-specific text classification or treatment response predictions. Retrieval introduces relevant context that refines decision-making.
How Does RAG Work? Technical Breakdown
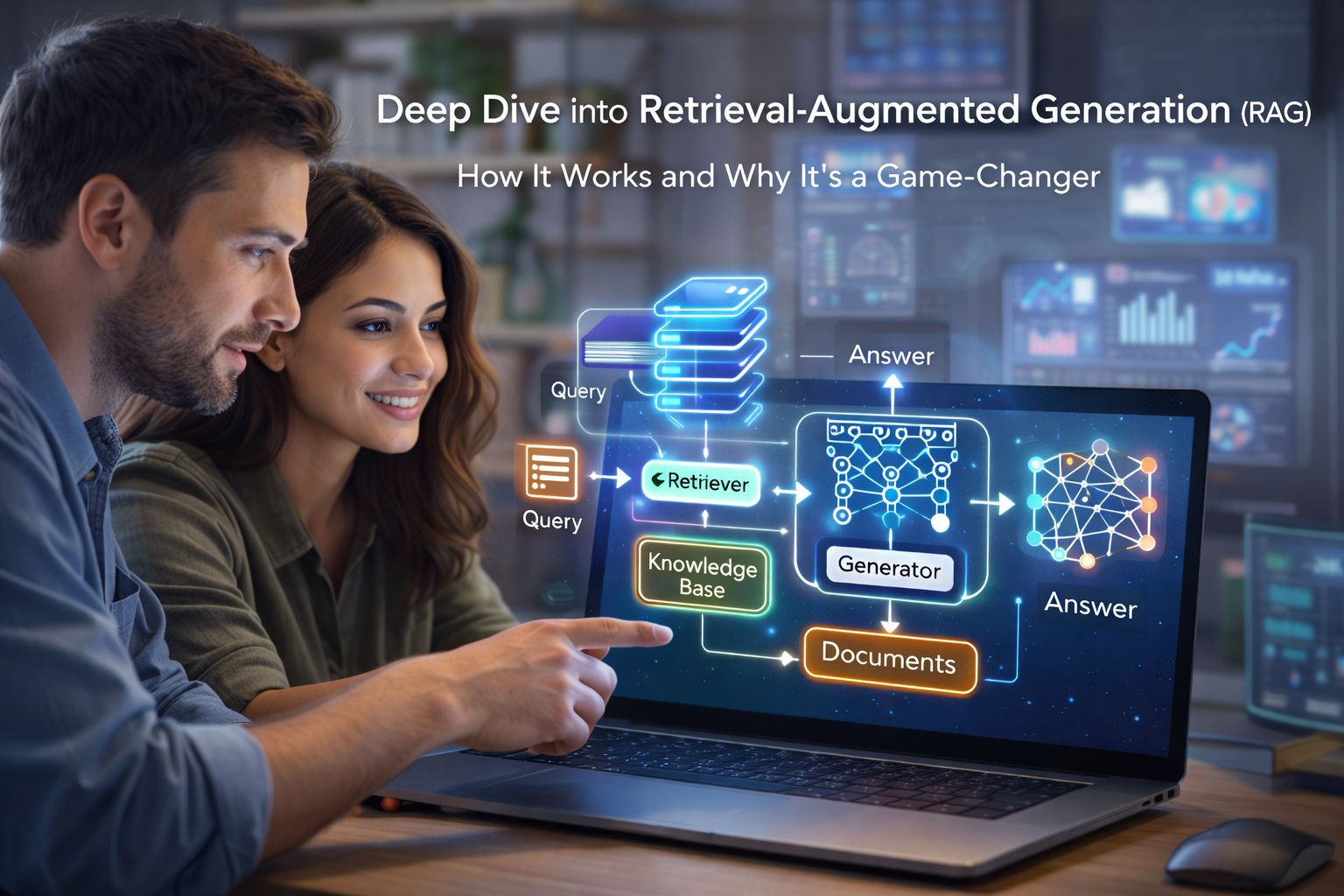
At its core, RAG combines two main components:
- Retriever: This module searches a large corpus or knowledge base using the input query, pulling back relevant documents or pieces of information.
- Generator: Given the retrieved documents and the original query, it produces the final response.
Step 1: The Query Comes In
For example, a system might receive a patient note or a robotic task instruction.
Step 2: Retrieval of Relevant Passages
The retriever uses a similarity search mechanism, often via dense vector embeddings, to find the top-k relevant documents or excerpts. These knowledge sources can be anything from external biomedical ontologies, previous robotic logs, to standardized guidelines.
Step 3: Conditioning Generation
The generator (usually a transformer-based neural network) takes the query plus the retrieved documents as input and generates output—answers, instructions, or classifications.
Technically, the generator’s attention mechanism can directly focus on retrieved snippets, blending retrieved facts with learned patterns.
Step 4: Fine-Tuning and Iteration
Fine-tuning the generator on domain-specific tasks, possibly with supervision signals or human feedback, further improves output quality. Iterative refinement, including regret-based optimization, helps minimize errors over time.
Practical Example: Medical Language Models
Consider a medical LLM designed for oncology documentation (e.g., TNM staging or treatment response prediction). Due to the sheer complexity and specialized vocabulary, pretrained general models struggle with precise understanding.
By deploying RAG:
- The system retrieves relevant medical ontology entries, clinical trial reports, or patient history segments.
- It then fine-tunes generation with oncology-specific instruction tuning.
- Handling tasks like entity recognition or relation extraction becomes more accurate because the model isn’t guessing blindly but grounding its output in retrieved knowledge.
This process dramatically improves precision and real-world usability.
Use Cases Across Domains
- Robotics: Enables robots to access task manuals or prior experiences dynamically, improving decision-making and learning from human corrections.
- Medical AI: Overcomes data sparsity by retrieving and incorporating specialized knowledge, reducing hallucinations and boosting diagnostic accuracy.
- Multilingual Tasks: Integrating retrieval and knowledge graphs with bilingual instruction tuning helps models navigate clinical texts across languages—even with minimal supervision.
Implementation Notes & Tools
- Knowledge Bases: Large, curated databases (e.g., biomedical ontologies, technical manuals) are indexed with vector search engines like FAISS or Chroma.
- Retriever Models: Dense passage retrievers or BM25 for similarity searches.
- Generator Models: Transformer-based text generation architectures (e.g., BART, T5).
- Fine-tuning: Use domain-specific instruction tuning and supervised learning for task alignment.
- Integration: Frameworks like Hugging Face’s
transformersanddatasetslibraries support building RAG pipelines.
Here’s a simplified pseudo-code snippet illustrating the flow:
# Retrieve documents
retrieved_docs = retriever.retrieve(query, top_k=5)
# Generate answer conditioned on retrieved docs
answer = generator.generate(input_text=query, context=retrieved_docs)Limitations and Challenges
- Latency: Retrieval steps add complexity and can slow down real-time applications unless well optimized.
- Quality of Knowledge Sources: Garbage in, garbage out—if retrieval pulls poor or contradictory info, generation suffers.
- Domain Adaptation: Requires good indexing and retrieval strategies tailored to the field.
Summary
Retrieval-Augmented Generation elegantly blends retrieval and generation to push AI capabilities beyond static knowledge. It’s proving critical in enabling models to dynamically access and leverage specialized, updated data—enhancing accuracy and adaptability across medical, robotic, and multilingual applications.
By integrating RAG with fine-tuned transformers and learning mechanisms like regret-based optimization, we get AI systems that learn continuously, optimize tasks effectively, and provide grounded, trustworthy outputs.
If you’re looking to build domain-specific generative models or adaptive AI systems, incorporating RAG principles is a smart move that balances technical sophistication with practical impact.